
Polar is the Ecommerce Connector for Claude

TL;DR
The semantic layer that makes your Shopify, ads, and subscription data actually usable in Claude without stacking MCPs or pasting CSVs.
Something has shifted in the last few months. Operators who were skeptical of AI a year ago now have Claude open in a tab all day. Agencies are building weekly exec summaries in it. Finance teams are modeling in it. Founders are running Monday-morning reviews in it.
And yet and this is the thing that keeps surprising us most DTC brands still don't connect their actual business data to Claude. They ask Claude questions about their business by pasting numbers into the chat. Or they don't ask at all, because pulling clean data out of Shopify, Meta, Klaviyo, and Amazon into a shape Claude can reason about is harder than it looks.
This post is about closing that gap. And about why the way most people are trying to close it stacking platform MCPs, or uploading CSVs doesn't work.
Everyone is about to install Claude. Then what?
A client team came up on a call last week. Smart operators. Real multi-channel business 95+ retail doors, a healthy ecommerce engine, the works. And they weren't using Claude internally. Not because they didn't want to. Because nothing about their data was ready for it.
That's the pattern. The adoption curve for Claude in DTC isn't being gated by skepticism anymore. It's being gated by plumbing. Every merchant is going to install Claude in the next few months. Every one of them is going to want to ask questions about their business. And the moment they try, they run into the same wall: their data lives in fifteen places, each place defines its own version of "revenue" and "CAC," nothing agrees, and Claude can't reason across any of it.
Closing that gap is worth owning. The merchants who get there first will operate with a very different speed and leverage than the ones who don't. And the way they get there matters because the shortcuts that look appealing right now are the ones that lock you into bad answers at scale.
The three broken ways people try to use Claude with their data
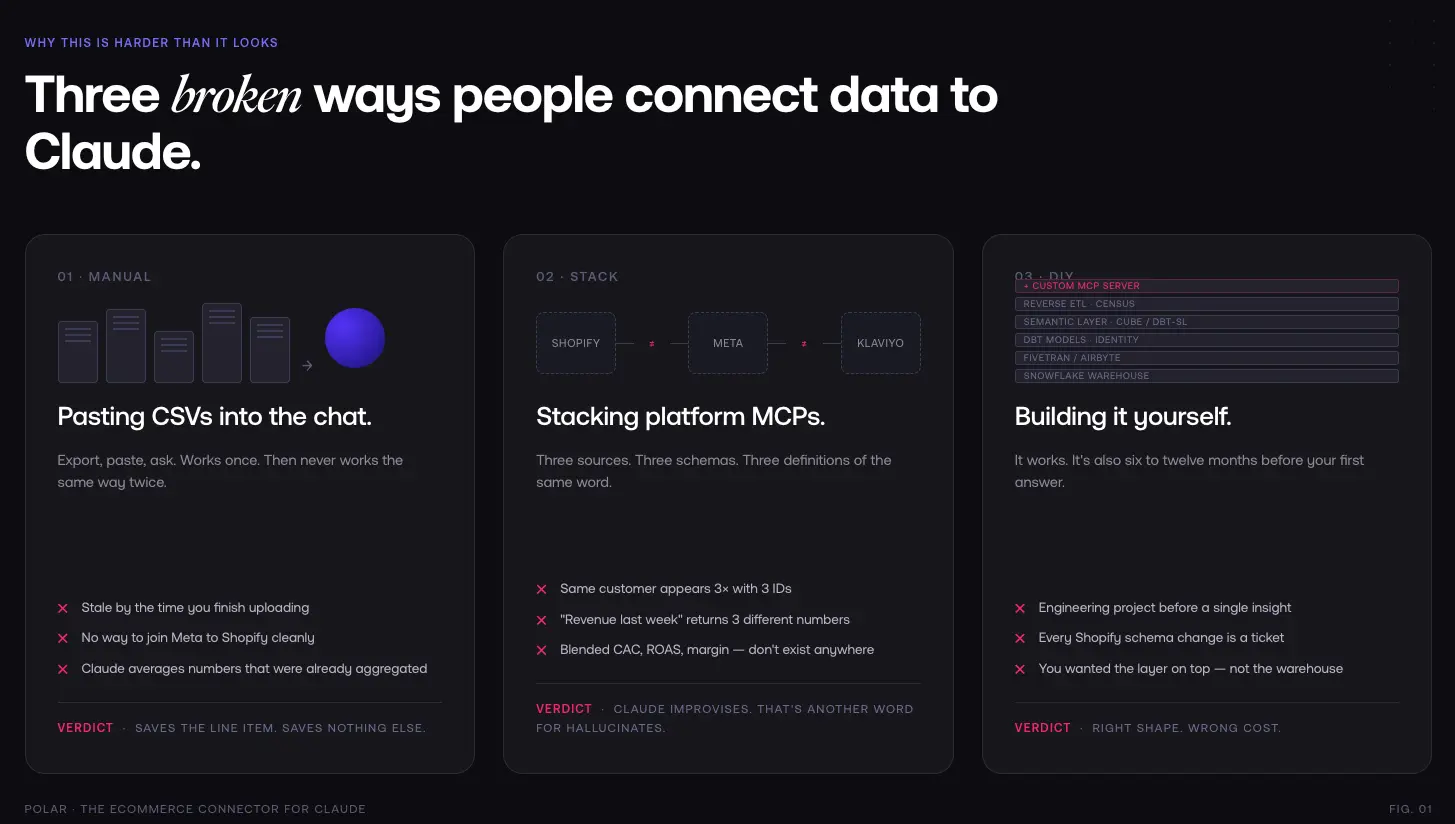
1. Uploading CSVs manually
The fastest thing, and the worst thing. You export from Shopify, export from Meta, export from Klaviyo, paste it all into a Claude conversation, and ask your question. It kind of works, once. Then:
- The data is already stale by the time you finish uploading it.
- You can't join anything cleanly Meta's "conversion" isn't Shopify's "order," and neither maps to your net revenue the way your finance team defines it.
- You can't ask for a follow-up a week later without redoing the whole dance.
- Claude confidently averages things it shouldn't average, because it has no way of knowing which numbers were already aggregated upstream.
This is the "save the money" path. It saves the line-item cost. It doesn't save anything else.
2. Stacking platform MCPs
This is the one that seems clever and isn't. Shopify has an MCP. Meta has an MCP. Klaviyo has an MCP. You install all three in Claude and figure Claude will do the rest.
Claude won't do the rest. Here's what actually happens:
- Each MCP returns data in its own schema, with its own naming, its own timezone handling, its own attribution window.
- The same customer appears three times, with three IDs, with no way to stitch them.
- "Revenue last week" returns three different numbers from three different sources, and Claude has to guess which one you meant.
- Blended metrics blended CAC, blended ROAS, contribution margin don't exist anywhere in those raw API responses. They have to be constructed. Claude tries to construct them on the fly, and gets them wrong, because LLMs are bad at doing arithmetic across disjointed tables.
- Historical data is whatever each platform's API is willing to paginate back through. You can't ask "how did this cohort perform over 12 months" because Meta's API will time out first.
The deeper problem: none of these MCPs know what a business entity is. Shopify's MCP knows about orders. Meta's knows about campaigns. Klaviyo's knows about flows. None of them know what your customer is. None of them knows what contribution margin means in your P&L. That shared understanding has to live somewhere, and if it doesn't, Claude improvises which is another word for hallucinates.
3. Building it yourself
This is the path for the teams that see the problem clearly. Spin up Snowflake, wire in Fivetran or Airbyte for ingestion, write dbt models, stand up a semantic layer (dbt Semantic Layer, Cube, or roll your own), glue in identity resolution, add reverse ETL with Census, then finally expose it to Claude through a custom MCP server.
It works. It's also a six-to-twelve-month engineering project, minimum, before you answer your first question. And the maintenance never stops every Shopify schema change, every Meta API deprecation, every new attribution window is a ticket.
Most DTC teams don't have that engineering capacity. The ones that do usually discover halfway through that what they wanted wasn't a warehouse it was the thing sitting on top of the warehouse that makes the data mean something.
What a real Ecommerce connector for Claude looks like
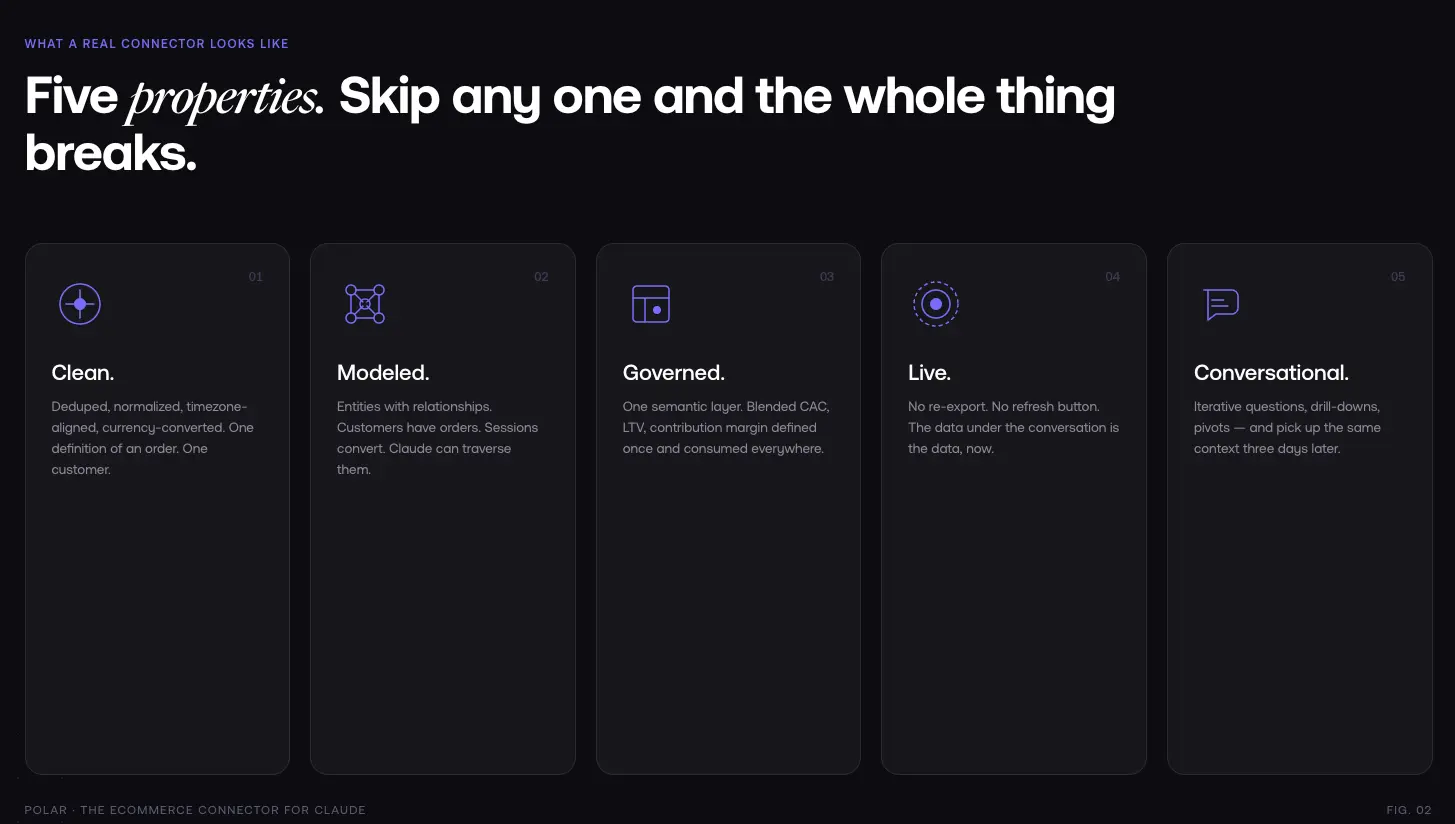
If CSVs are too flat, stacked MCPs are too fragmented, and DIY is too expensive, what does the right answer actually look like?
Five properties. Skip any of them and the whole thing breaks.
Clean. The data has to be deduplicated, normalized, timezone-aligned, and currency-converted across every source. One definition of an order. One definition of a customer. One definition of spend.
Modeled. Not just cleaned rows actual entities with relationships. Customers have orders. Orders have line items. Campaigns drive sessions. Sessions convert to orders. Claude has to be able to traverse those relationships to answer anything non-trivial.
Governed by a semantic layer. This is the piece nobody thinks they need until they try to operate without it. A semantic layer is where your business metrics are defined once blended CAC, LTV, contribution margin, net revenue after returns and consumed everywhere. When Claude asks for "CAC," it gets your definition of CAC, not whatever it reconstructed from raw columns. That one property is the difference between answers you can act on and answers you have to double-check.
Live. No manual refresh, no "let me re-export the CSV." The data under the conversation is the data, now.
Conversational. Claude has to be able to ask iterative questions, drill down, pivot, and come back three days later in a new conversation without losing context. That means the connector can't just dump a table it has to expose tools Claude can reason over: get context, generate a report with these metrics and dimensions, pull this specific dashboard, filter by this view.
Those five properties, together, are what we mean by "ecommerce connector for Claude." Everything else is a shortcut that breaks under real-world use.
How Polar works as your Claude connector
This is what Polar has been building toward for four years, long before MCP existed as a standard. The pieces:
.webp)
The data layer. Every Polar customer gets their own dedicated Snowflake instance, their data, portable, not locked into a black-box SaaS. 45+ native connectors pull in Shopify, Amazon, Walmart, Meta, Google Ads, TikTok, Klaviyo, and the rest. Fivetran and Airbyte cover the long tail. Custom SDKs handle the edge cases. The Polar Pixel captures first-party events from your own domain. Identity resolution (Lifetime ID) stitches customer journeys across devices and sessions.
The semantic layer. On top of the warehouse, Polar maintains a pre-built ecommerce ontology LTV, blended CAC, contribution margin, blended ROAS, net revenue, cohort retention, dozens more computed automatically, editable to match your specific business logic. Your definitions live here, not in a prompt. Claude queries concepts, not columns.
The Polar MCP. This is where the semantic layer connects to Claude. The MCP exposes a focused set of tools:
- Get context tells Claude your company name, currency, timezone, connected data sources, available metrics, and dimensions. Grounding, every conversation.
- Generate report pulls trusted numbers with explicit metrics, dimensions, date ranges, filters, and ordering. Includes totals so Claude doesn't have to sum rows (which is where most MCPs start hallucinating).
- List dimensions surfaces every attribution model, custom dimension, and saved view you've defined in Polar.
- List dashboards / Get dashboard details lets Claude pull any dashboard or report you've built, summarize it, and deep-link back into Polar so you can audit the underlying data in one click.
- Pre-built prompts one-click starting points for Executive Summary, Inventory Optimization, Profitability Deep-dive, CRO, Email Revenue, Creative Performance, and Media Buying Health Check.
The trust layer. Every answer Claude gives is traceable. When the MCP returns a number, that number came from a specific generate_report call against specific metrics in your semantic layer against specific underlying rows in your Snowflake. You can click back to the source. No black box.
A quick example from a customer using this in production: During a recent session, a merchant kept pushing Claude to investigate a sales drop. Claude, through the Polar MCP, eventually surfaced a two-year-old discount code with no single-use rule that had been abused hundreds of times. That kind of answer requires clean historical data, joined customer and order entities, and a metric (discount impact) that's defined consistently. None of that is reconstructable at query time from platform MCPs.
What changes when your data is properly connected

The use cases that were theoretical a year ago are the boring default now.
Monday-morning executive summary. One prompt, delivered as a doc, pulled live from your semantic layer: net sales vs. plan, blended ROAS by channel, top movers, anomalies flagged, tied back to last week's actions. An agency partner generates this weekly for clients using the Executive Summary prompt. What used to take a PM half a day takes about thirty seconds.
"Why did this drop?" investigation. Not a dashboard, a conversation. Claude pulls the data, notices the shape of the drop, pivots to the dimensions most likely to explain it, checks attribution, checks product mix, checks promos. By the end you have a root cause with a number attached. Another team using Polar runs this pattern an hour or two a day; they built a Claude dashboard that refetches Polar data when filters change something that's never existed inside a BI tool.
Cohort and retention questions that used to need SQL. "Show me 12-month retention for customers acquired through Meta in Q3 2024 vs. Q3 2025." No analyst ticket. The semantic layer already has cohort definitions; Claude just composes them.
Agentic workflows. This is where it gets fun. Scheduled prompts inside Claude that fire every Monday, query the Polar semantic layer for the last seven days, write prioritized actions into a Notion task tracker, flag anything that needs a human. Or scan for anomalies daily and post to Slack. Or generate a podcast for the CEO. One prompt per agent. All of them grounded in the same governed data.
Finance and ops, not just marketing. Once the data is modeled, the audience opens up. Finance lives in Excel Claude for Excel + Polar MCP puts real-time net revenue and contribution margin next to their models. Ops wants weekly reports across Shopify, NetSuite, and ShipHero, Claude pulls them without a dashboard having to exist first.
The pattern underneath all of these: when a business's data is properly modeled, the possibility space for what Claude can do expands enormously. And it doesn't require any of your team to know SQL. The trend operators keep talking about right now "one-person teams," agentic-first workflows, doing more with less headcount is downstream of this. You can't run a lean team on bad data.
A note on open standards
MCP is an open protocol. Polar's MCP works in Claude, ChatGPT, Lovable, n8n, Make, and more. We're not trying to lock anyone into a specific assistant your data is yours, your warehouse is yours, the MCP speaks a standard.
But Claude is where we're putting our weight. The reasoning is practical: Claude is the assistant our customers are adopting fastest, it handles tool use more reliably than alternatives today, and Anthropic is investing in it as a work surface (Claude for Excel, skills, agents) rather than a chatbot. If that shifts, the semantic layer underneath moves with you. That's the whole point of not being locked to one interface.
Get started
Connecting Polar to Claude is a few minutes of setup. If you're already on Polar, it's one click from the Connectors menu in Claude. If you're not, the install path is:
- Sign up at polaranalytics.com, connect your first data sources (Shopify + one or two ad platforms is enough to start).
- Add Polar as a custom connector in Claude (guide: Using Polar MCP in Claude).
- Open a conversation. Try "give me an executive summary of last week" or pick one of the pre-built prompts.
That's the whole thing. Your data, clean, modeled, live, connected through a semantic layer to the assistant your team is about to live in.
Table of contents
Frequently asked questions
_%20What%20It%20Is%2C%20How%20to%20Calculate%20It%20%26%20Tactics%20to%20Boost%20It.webp)
_%20Formula%2C%20Benchmarks%20%26%20How%20to%20Lower%20It%20on%20Shopify%20(1).webp)


