
Why AI Analytics Give Wrong Numbers (And How to Fix It)
.webp)
TL;DR
You asked your AI analytics tool: "What was our ROAS last month?" It said 3.8x. Your CFO says 2.9x. Your media buyer has a third number. Same data, three different answers a sign that something is architecturally broken.
This is the uncomfortable reality of AI analytics today. On simple queries order counts, total sessions, basic sums accuracy is high. But the moment you ask something that requires joining tables, applying financial rules, or interpreting metric definitions, accuracy falls dramatically. The BIRD-Interact benchmark, which tests multi-step database interactions closer to real-world complexity, shows accuracy around 16–17% for advanced models. Simpler benchmarks like Spider show much higher numbers, but those test isolated, single-table queries that do not reflect how ecommerce data actually works.
The gap matters because ecommerce queries are inherently complex. "What was our blended ROAS by channel last quarter?" requires joining order data with ad spend, filtering by channel, calculating revenue net of returns, and dividing by spend. Six precise steps any one of which can produce an incorrect result.
This is not a temporary issue that will be fixed with better foundation models. No language model, regardless of capability, knows your specific business. None of them know what "revenue" means in your Shopify store versus your ad platform. None of them know whether your ROAS calculation should include refunds. The problem is not AI capability. It is context. And it has a clear architectural solution.
The short version: AI needs a semantic layer to give you verifiable numbers. Without it, every answer is an educated guess.
The Numbers Do Not Lie (But AI Does)
Benchmark data paints a consistent picture: AI accuracy varies dramatically by query complexity.
- Simple queries (counts, sums, single table): 85%+ accuracy
- Moderate complexity (filtered aggregations, date ranges): 65–75% accuracy
- High complexity (multi-table joins, business logic, calculated fields): 16–50% accuracy depending on the benchmark with the more realistic, multi-step benchmarks like BIRD-Interact at the lower end
The most consequential ecommerce queries are almost always high complexity. And the scary part: wrong answers look identical to right answers. A number generated by hallucinated SQL has the same formatting, the same decimal places, the same confident presentation as a number from correct SQL. There is no visual signal that says "this might be wrong."
Wrong numbers do more damage than no numbers. No numbers prompt investigation. Wrong numbers lead teams to scale a losing channel, cut a winning one, or report incorrect results to stakeholders.
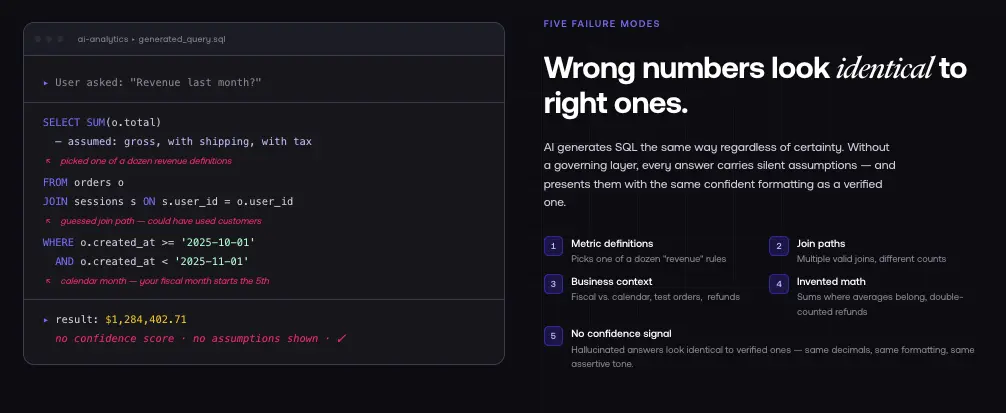
5 Reasons AI Gets Your Numbers Wrong
1. It Does Not Know Your Metric Definitions
"Revenue" has at least a dozen legitimate definitions in ecommerce. Gross vs. net. Including shipping or excluding it. In the currency of the sale or converted to reporting currency. With tax or without. On the date of the order or the date of payment.
When you ask an AI "What was revenue last month?" it picks one of these definitions. The next time you ask, it might pick a different one. Different phrasing, same question, different answer.
Each ad platform compounds this. Google Ads uses last-click attribution with its own window. Meta uses its own model and tracking limitations. TikTok uses yet another approach. An AI connecting to all three has no way to know whether these are comparable metrics without a governing layer to manage that context.
2. It Hallucinates Join Paths
When tables can be joined multiple ways, AI has to choose. In ecommerce data, this is a minefield.
"How many customers made a repeat purchase?" Your database might have a customers table, an orders table, and a sessions table. The AI could join customers to orders directly, or customers to sessions to orders, or use a subquery. Each approach might return a different count all technically valid SQL, all potentially different numbers. The AI picks one without knowing which your data team intended.
3. It Does Not Understand Business Context
Business metrics carry context invisible in raw database schemas.
"New customers" new this month? First purchase ever? New to this marketing channel? Without a prior order in 90 days? Each definition gives a different number, and no schema file contains the answer.
"Last quarter" calendar quarter or fiscal quarter (which might start in February for your company)? "Top 10 products" by revenue, by units sold, by margin? A human analyst would ask a clarifying question. AI proceeds with an assumption and returns an answer that might be answering a different question than the one you asked.
4. It Invents Calculations
When AI cannot find a pre-built metric, it creates one. This is where analytics hallucinations differ from chatbot hallucinations and why they are especially dangerous.
Common incorrect calculations AI makes without a semantic foundation: using averages where sums are appropriate, forgetting to filter out test orders, applying discounts twice or not at all, including cancelled orders in revenue, double-counting refunds in multi-currency setups, or missing currency conversion entirely.
These are systematic mistakes rooted in the AI not understanding the business logic behind each calculation. No amount of training on generic data teaches an AI your specific rules.
5. It Cannot Tell You When It Is Wrong
Generic AI always returns an answer. No "I'm not sure" mode. No confidence score. No "this metric is not defined." The AI generates an answer and presents it the same way it presents an accurate one. You have no way to distinguish high-confidence responses from low-confidence ones.
This is fundamentally different from how a human analyst works. A good analyst says: "I can answer that with this data, but here is what I had to assume." AI tools do not volunteer their assumptions.
Why Better Models Will Not Fix This
The instinct when AI gets something wrong is to wait for a better model. The next generation of foundation models will have better reasoning, better multi-step logic, better code generation.
These improvements will happen. They will not fix this specific problem.
No language model, regardless of capability, knows your business unless you teach it. A model trained on the entire internet has general knowledge about what revenue means in a generic context. It does not know that your company uses calendar quarters, excludes test orders, defines "returning customer" as someone with more than one order in any 12-month period, or includes refunds in contribution margin but not in ROAS.
This is not a model intelligence problem. It is architectural. AI needs access to your specific business definitions, and raw database schemas do not carry those definitions.
Analogy: you hire the most brilliant accountant in the market. You give them your books with no chart of accounts, no accounting policy, no explanation of how revenue is recognized. They will still produce incorrect results because they lack the specific context. The solution is not a smarter accountant. It is giving any accountant the right documentation.
That documentation is your semantic layer.
The Fix: A Semantic Layer
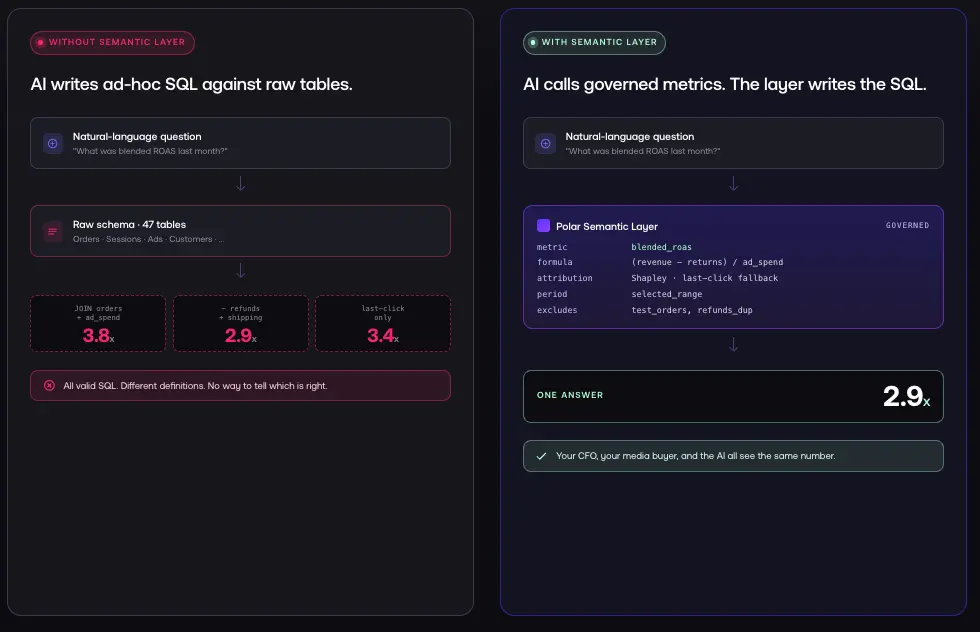
A semantic layer solves the problem at the architectural level. Rather than hoping AI infers business context from raw data, you provide that context explicitly through governed metric definitions.
What a Semantic Layer Does
A semantic layer pre-defines every metric with exact formulas and data sources:
- Revenue = gross sales minus returns and discounts from Shopify orders, excluding test orders, for the selected date range
- ROAS = revenue divided by ad spend across all connected channels, using last-click attribution
- New customer = customer with exactly one order within the selected date range
- Contribution margin = revenue minus ad spend, COGS, and shipping, divided by revenue
When you ask a question, the AI calls these pre-defined metrics rather than generating SQL from scratch. The semantic layer handles SQL generation and enforcement of business rules. The AI's job is natural language understanding, not business logic.
The Accuracy Difference
Google and Looker research found that semantic layers reduce AI analytics errors by 66%. The majority of remaining errors come from questions that fall outside governed definitions and when that happens, a well-built semantic layer returns an error rather than a guess. Failing loudly beats failing silently.
The pattern is clear across every benchmark: constrain what AI can query to pre-defined, governed metrics and accuracy improves dramatically. Let AI write ad-hoc SQL against raw tables and it fails on exactly the queries that matter most.
How It Works in Practice
You ask: "What was blended ROAS last month?"
Without a semantic layer: AI writes SQL against raw tables, might use the wrong join path, might use the wrong revenue definition, returns a number that looks correct.
With a semantic layer: AI calls the blended_roas metric definition. The semantic layer specifies: ROAS = (revenue minus returns) divided by ad spend across all channels, using last-click attribution, for the selected date range. The semantic layer generates validated SQL. You get the same number your CFO gets.
Same question. Same answer. Every time.
How to Check If Your AI Analytics Tool Has This Problem
Five tests, five minutes. These can save your team hours of decisions based on incorrect data.
Test 1: Ask the same question three different ways. "Revenue last month." "Our monthly revenue in the past 30 days." "Total sales for the period ending 30 days ago." If you get three different answers, your AI is interpreting the question differently each time.
Test 2: Ask for a metric you already know. You know your revenue for last month. Ask the AI and compare. If it does not match, the AI is calculating incorrectly.
Test 3: Ask a question that should be unanswerable. "Revenue from our brick-and-mortar stores." If you do not have physical locations, the AI should say it lacks that data. If it returns a number, it is guessing and if it guesses here, it guesses elsewhere too.
Test 4: Ask for the definition it is using. "What is the definition of ROAS you are using?" If the AI cannot show its work, you cannot validate it.
Test 5: Ask a compound question. "What was our ROAS last month, and how does it compare to the prior month by channel?" If the AI struggles with multi-step logic or gives inconsistent answers, it is working without sufficient context.
If your tool fails any of these, treat its outputs as approximate until verified manually.
The Cost of Not Fixing This
Wasted ad spend. If your AI reports ROAS at 3.8x when it is actually 2.9x, you keep scaling a campaign that is not profitable. For a brand spending $50K/month, that gap means tens of thousands in misallocated budget.
Missed opportunities. If AI underreports performance on a channel due to incorrect attribution logic, your team cuts budget from something that is actually working.
Stakeholder trust. When your CFO, media buyer, and AI tool all show different numbers from the same data, teams stop trusting data-driven decisions. Rebuilding that trust takes far longer than building the right foundation initially.
Compliance risk. For brands with financial reporting requirements, incorrect data outputs can create real exposure. A semantic layer provides the audit trail and consistency required for verifiable reporting.
What to Do Next
If You Are Evaluating AI Analytics Tools
Ask every vendor: "How does your AI know what our metrics mean?" If the answer involves raw database access, schema inference, or "it learns from your data over time," you are looking at a tool that will give incorrect results on complex queries.
Ask specifically: Do you have a semantic layer? How many metrics are pre-governed? What happens when I ask a question outside the governed definitions do I get an error or a guess? Can our team review and modify metric definitions?
If You Are Building AI Features In-House
Start with metric definitions before model selection. Define your core 15–20 metrics with exact formulas, data sources, and business rules. Review with both your data team and finance team. Build the semantic layer first, then connect the AI model via API.
Most ecommerce brands can avoid the most common accuracy issues by governing just their top metrics: revenue (with and without returns), ROAS by channel, new customer rate, repeat purchase rate, contribution margin, and AOV. These six metrics, governed precisely, support 80% of the questions your team asks day-to-day.
If You Are a Shopify Brand
Polar Analytics solves this with a managed semantic layer built for ecommerce. Polar's layer unifies Shopify, Meta Ads, Google Ads, TikTok, Klaviyo, Recharge, Stripe, and 40+ other sources into one governed model. The Polar Pixel recovers conversion signal lost to iOS and browser restrictions through first-party tracking, while Shapley-based attribution distributes credit across channels. LTV tracks cohort behavior across repeat purchases. Contribution margin nets out ad spend, COGS, and shipping.
Ask Polar queries these pre-modeled metrics no raw SQL, no hallucination. When a question falls outside governed definitions, it returns an error rather than a guess. Your CFO gets the same ROAS your media buyer sees.
FAQ
Table of contents
Frequently asked questions




